Partner Solutions
Splunk®
Integrate disconnected IBM i and mainframe systems in Splunk for a true enterprise-wide view of security and IT operations
Drive better decisions – faster – with a single, real-time view
Splunk is known as the “Data-to-Everything™” platform, bringing data to every question, decision and action. But Splunk doesn’t natively interact with your IBM mainframe and IBM i systems – creating a blind spot that can hinder your IT operations and security analytics.
Traditional IBM systems power mission-critical applications around the world. But many organizations are still flying blind, with no easy way to derive operational intelligence from the vast amounts of machine data generated by these critical systems.
Precisely Ironstream makes it simple to securely collect, transform and forward log data from these traditional IBM systems to Splunk, where it’s merged with machine data from across your infrastructure.
Ironstream delivers real-time, total visibility, without the need for redundant, siloed tools, or specialized IBM mainframe or IBM i expertise.

You can’t manage what you can’t see.
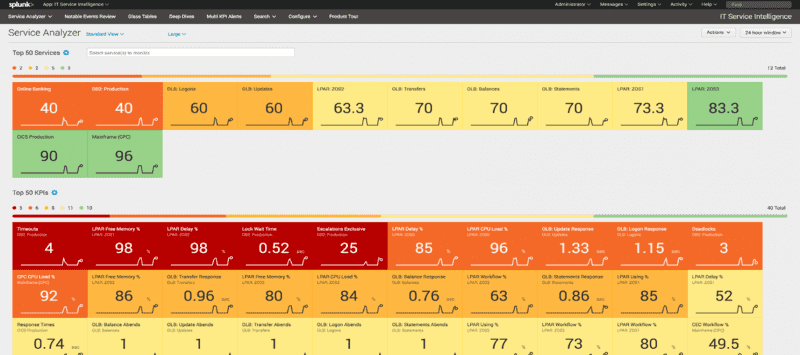
Splunk’s powerful IT operations analytics platform helps gives you the visibility you need to optimize the performance and availability of IT systems and applications, while controlling IT costs and resources.
Since your enterprise’s IT operations span both traditional IBM systems and distributed systems and cloud computing resources, you need an IT operations analytics (ITOA) solution that does as well.
But mainframe and IBM i systems have been left out of most Splunk environments because the machine data they generate is unique and requires specialized skills.
Precisely Ironstream collects and streams critical operational and machine data from traditional IBM systems to Splunk, where it is correlated with data from the rest of your enterprise. With Ironstream for Splunk you can turn machine data into valuable insights.
Learn more about IT operations analytics
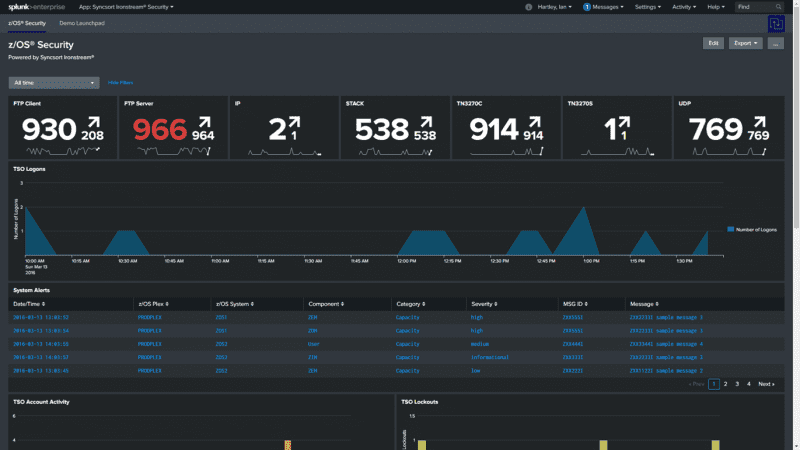
Splunk is a powerful platform for monitoring, integrating, analyzing and visualizing security data from across the enterprise. It’s critical to include the mainframe and IBM i in this comprehensive view.
Ironstream continually collects security data from a wide range of IBM mainframe and IBM i sources, transforms it, and forwards it to Splunk in real-time. Once in Splunk, you can analyze the information in the context of your overall enterprise IT infrastructure.
Access patterns, authorization failures, user behavior and other security-related information from these platforms help you detect and prevent potential security breaches no matter where they occur.
With Ironstream and Splunk, you can quickly and easily identify deviations from security best practices and maintain an audit trail to satisfy security officers and auditors.
Learn more about Security Insights and Event Management (SIEM)
Get a complete view of your IT landscape
To manage today’s IT infrastructure, you need to have a single, comprehensive view of all the systems in your environment. Splunk is the IT platform of choice for many companies but it does not support the collection of machine data from traditional IBM mainframe and IBM i systems.
Precisely Ironstream makes it simple to collect, transform and securely stream data from these traditional IBM platforms into Splunk with no need for mainframe or IBM i expertise.
Ironstream is the industry’s leading automatic forwarder of z/OS mainframe log data and IBM i machine data to Splunk, where it’s merged with other machine data from across your IT infrastructure. This consolidated view powers enterprise-wide IT Operations Analytics (ITOA), Security Information and Event Management (SIEM) and IT Service Intelligence (ITSI).