
Data Governance or Data Quality: Which to do First?
Many companies are just starting their data governance journey. There has been a paradigm shift towards a data driven environment. As you start to think how data impacts your organization, it becomes clear that the focus is leaning more towards business processes and away from specific applications. Quite often I speak with prospects who are traditional IT and are trying to make sense of data governance and the related data quality rules.
Remediation of data quality issues in a data governance instance is quite different than with traditional IT focused data quality. The business side of an organization is focused on a business process and wants to be empowered to manage and access that data. The older paradigm of siloed data does not translate well to this model.
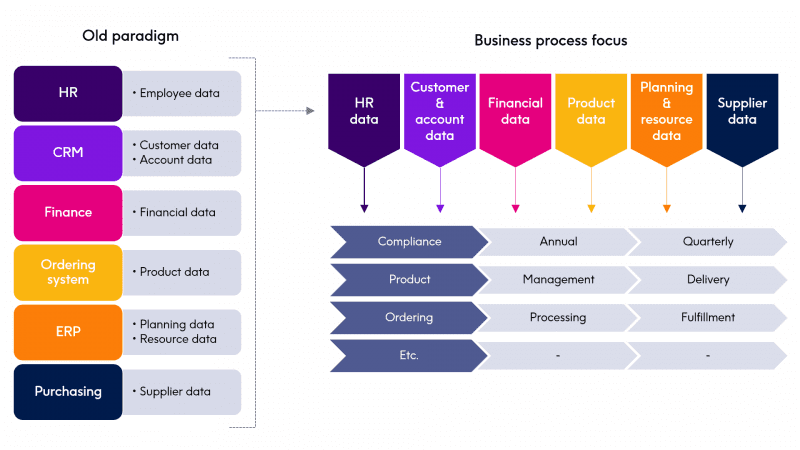
The business side of an organization typically wants to have a structure in place that allows for an understanding and trust of the data without the burden of supporting the infrastructure behind it. This is often a driving need behind starting a data governance journey.
When starting the data governance journey, what is the first step?
Most companies know what data, for the most part, they want to include in their data governance effort. They also most likely have time-consuming manual processes in place to manage the information. In addition, that information is closeted into a few departments, or sometimes it’s just tribal knowledge.
There is usually a gap between what the business needs and what the technical folks believes it needs to provide and often they do not understand each other’s perspective. The business can create whatever manner of policies, procedures, mandates, business rules, etc. that they require, but being able to ensure that this structure is validated by data quality is key.
So how can a company adjudicate their data governance efforts with data quality? It must start with data quality. A simple analogy would be that if you are acquiring a new swimming pool, would you fill it with clean water or dirty water?
Businesses can identify and determine access of the data already, even if they are performing it manually. You must be sure you can trust that data.
Read our eBook
Fueling Enterprise Data Governance with Data Quality
See how data quality is strengthening the overall enterprise data governance framework
How can business rules be set to ensure data quality is adhered to?
With most data governance initiatives, the business is focusing on Critical Data Elements (CDEs)/Key Data Elements(KDEs). I have seen these number from approximately 2000 CDEs on the high side to as little as 40 on the lower side.
The desired business rules to support these Critical Data Elements can be numerous. It is a challenge, to say the least, to attempt to have a technical rule solution that requires the business to wait for technical folks to understand, much less create, their desired rules. The business folks want to be able to be empowered to create their own rules. In fact, they have already created these rules in a manual, often in ‘plain English.’ Business users need a tool simple enough for them to feel comfortable in creating rules yet allows for the supporting certification of the data quality for the CDEs.
This is a natural first step towards data governance. Taking ownership of the data starts with taking ownership of the rules behind it.
Data profiling and data cleansing is another data quality step that must be secured before beginning a data governance pilot or program. An organization has a need to understand what data they have – and be able to trust the data – in order to ensure that CDEs can be certified.
Clearly, a data governance initiative, whether it starts with a software tool or just a process, some spreadsheets and a data governance council, requires solid data quality in place first. There must be rules to support Critical Data Elements and these rules must be easily created by the business people who are closest to the usage of said rules. This allows for rapid certification of key reports containing those critical data elements as well as confidence and self sufficiency.
For more information, read our eBook: Fueling Enterprise Data Governance with Data Quality

Insurance Organizations Depend on the Quality of Their Data
Insurance is an inherently data-driven industry. Even before the age of advanced analytics, experts in the industry were routinely using data to assess risk and price policies. Today, data analytics...

Data Quality Dimensions: How Do You Measure Up? (+ Downloadable Scorecard)
Virtually every business leader understands just how valuable data can be for driving innovation, increasing revenue, improving customer satisfaction, optimizing processes, and achieving...

Validation vs. Verification: What’s the Difference?
To a layperson, data verification and data validation may sound like the same thing. When you delve into the intricacies of data quality, however, these two important pieces of the puzzle are...